Interfacing with scikit-learn¶
Using survivalpredict’s pipeline to interface with the sklearn ecosystem.
Survivalpredict’s SklearnSurvivalPipeline class allows us to interface directly with scikit-learn’s greater ecosystem. There is a whole ecosystem centered around hyperparameter tuning, feature selection, and scaling out compute for scikit-learn compatible code that we can interface with.
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import itertools
import pandas as pd
from sklearn.model_selection import GridSearchCV , cross_val_score
from sklearn.compose import make_column_transformer, make_column_selector
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from mlxtend.feature_selection import SequentialFeatureSelector
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
from survivalpredict.estimators import CoxProportionalHazard,KaplanMeierSurvivalEstimator
from survivalpredict.metrics import integrated_brier_score_administrative_sklearn_scorer
from survivalpredict.pipeline import SklearnSurvivalPipeline,build_sklearn_pipeline_target,make_sklearn_survival_pipeline
from survivalpredict.strata_preprocessing import StrataBuilderEncoder, StrataColumnTransformer, make_strata_column_transformer
from SurvSet.data import SurvLoader
loader = SurvLoader()
Let’s start by loading in the data, using SurvSet. Notice that we are keeping the data as a dataframe. This allows us to retain feature names, enabling us to call out specific strata feature names when tuning for the best-performing strata.
df = loader.load_dataset("support2")["df"]
df = df.dropna()
times = df["time"].to_numpy().astype(np.int64)
events = df["event"].to_numpy().astype(np.bool_)
X_df = df[list(set(df.columns).difference(set(("pid", "event", "time"))))]
Next, we are going to determine the maximum point in time to observe for evaluating the model. As time goes forward, a smaller and smaller percentage of individuals will still be in the study, including the tail-end points in the integrated Brier score, which will artificially inflate the score, not highlighting improvements in performance in points in time that include most individuals.
max_time = np.percentile(times, 85).round().astype(np.int64)
The ‘build_sklearn_pipeline_target’ function allows us to take non-feature vectors, like times, events, times_start(for left censoring), and predetermined strata into a single vector that can be passed into scikit-learn classes. The output of ‘build_sklearn_pipeline_target’ will function as the ‘y’ vector for the SklearnSurvivalPipeline class.
Next, we will build a pipeline that will turn ‘fac_sex’, ‘fac_income’ columns into the strata, then preprocess the rest of the features, and finally train a Cox model.
y = build_sklearn_pipeline_target(times, events)
strata_transformers = make_strata_column_transformer(
(StrataBuilderEncoder(), ["fac_sex", "fac_income"])
)
column_transformers = make_column_transformer(
(StandardScaler(), make_column_selector(dtype_include=np.number)),
(OneHotEncoder(), make_column_selector(dtype_include=[object, "string"])),
)
pipeline_cox = make_sklearn_survival_pipeline(
strata_transformers,
column_transformers,
CoxProportionalHazard(),
max_time=max_time,
)
pipeline_cox
SklearnSurvivalPipeline(max_time=818,
steps=[('stratacolumntransformer',
StrataColumnTransformer(strata_transformers=[('stratabuilderencoder',
StrataBuilderEncoder(),
['fac_sex',
'fac_income'])],
stratabuilderencoder__columns=['fac_sex',
'fac_income'])),
('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
<sklearn.compose._column_transformer.make_column_selector object at 0x7f5dc0e4c2f0>),
('onehotencoder',
OneHotEncoder(),
<sklearn.compose._column_transformer.make_column_selector object at 0x7f5dc102e490>)])),
('coxproportionalhazard',
CoxProportionalHazard())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| steps | [('stratacolumntransformer', ...), ('columntransformer', ...), ...] | |
| max_time | 818 | |
| memory | None |
Parameters
| strata_transformers | [('stratabuilderencoder', ...)] | |
| stratabuilderencoder__columns | ['fac_sex', 'fac_income'] |
['fac_sex', 'fac_income']
Parameters
Parameters
<sklearn.compose._column_transformer.make_column_selector object at 0x7f5dc0e4c2f0>
Parameters
<sklearn.compose._column_transformer.make_column_selector object at 0x7f5dc102e490>
Parameters
Parameters
| alpha | 0.0 | |
| max_iter | 25 | |
| solver | 'newton' | |
| ties | 'breslow' | |
| tol | 1e-09 |
We can now use sk’s native cross_val_score, but we will need to pass in our own scorer
cross_val_score(
pipeline_cox,
X_df,
y,
scoring=integrated_brier_score_administrative_sklearn_scorer,
error_score='raise',
).mean()
np.float64(-155.14165982224978)
#we can also build a cox model without strata
cross_val_score(
make_sklearn_survival_pipeline(
column_transformers,
CoxProportionalHazard(),
max_time=max_time,
),
X_df,
y,
scoring=integrated_brier_score_administrative_sklearn_scorer,
).mean()
np.float64(-155.57987707062597)
Next, let’s compare this score agaist our KaplanMeier baseline.
cross_val_score(
make_sklearn_survival_pipeline(column_transformers,KaplanMeierSurvivalEstimator(),max_time=max_time),
X_df,
y,
scoring=integrated_brier_score_administrative_sklearn_scorer,
).mean()
np.float64(-179.90976086220107)
It looks like our first Cox models are not bad, we are performing better than KaplanMeier. We can now start hyperparameters and strata tuning.
#getting combinations of all categorical data
cat_cols = X_df.select_dtypes(pd.CategoricalDtype()).columns
#in case we wana look at strata combinations
cat_col_combinations = list(
itertools.chain.from_iterable(
itertools.combinations(cat_cols, i) for i in range(1, 3)
)
)
#, this makes gridsearch run faster
#cat_col_combinations = cat_cols
#you can take a look at all pram names and prameters with pipeline_cox.get_params()
param_grid = {
"stratacolumntransformer__stratabuilderencoder__columns": cat_col_combinations,
"coxproportionalhazard__alpha": [0, 10, 25, 50, 75, 100],
}
#running the sklearn native GridSearchCV, you can replace GridSearchCV with your favorite hyperprameter tunning class
gs = GridSearchCV(
pipeline_cox,
param_grid,
scoring=integrated_brier_score_administrative_sklearn_scorer,
n_jobs=5
)
#not all strata will be present in each cv split, this will cause errors/warnings; this should not be an issue, as sparse strata are not a good strata regardless
import warnings
with warnings.catch_warnings():
warnings.simplefilter("ignore")
gs.fit(X_df, y)
cv_results = pd.DataFrame(gs.cv_results_)
cv_results.sort_values('rank_test_score').head(5)[['params','mean_test_score','std_test_score','rank_test_score']]
| params | mean_test_score | std_test_score | rank_test_score | |
|---|---|---|---|---|
| 21 | {'coxproportionalhazard__alpha': 0, 'stratacol... | -120.107073 | 5.012660 | 1 |
| 153 | {'coxproportionalhazard__alpha': 25, 'strataco... | -120.348433 | 6.381001 | 2 |
| 68 | {'coxproportionalhazard__alpha': 10, 'strataco... | -120.893513 | 6.171047 | 3 |
| 2 | {'coxproportionalhazard__alpha': 0, 'stratacol... | -121.189043 | 5.495687 | 4 |
| 134 | {'coxproportionalhazard__alpha': 25, 'strataco... | -121.211370 | 7.280129 | 5 |
#the 'best' parameters.
cv_results[cv_results['rank_test_score'] == 1]['params'].values[0]
{'coxproportionalhazard__alpha': 0,
'stratacolumntransformer__stratabuilderencoder__columns': ('fac_sex',
'fac_sfdm2')}
strata_transformers = make_strata_column_transformer(
(StrataBuilderEncoder(), ('fac_sfdm2', 'fac_sex'))
)
sp_pipeline_cox = make_sklearn_survival_pipeline(
strata_transformers,
column_transformers,
CoxProportionalHazard(alpha=10),
max_time=max_time,
)
after tuning, we get a far better performing model.
cross_val_score(
sp_pipeline_cox,
X_df,
y,
scoring=integrated_brier_score_administrative_sklearn_scorer,
).mean()
np.float64(-119.85331470386677)
We are now going to experiment with feature selection.
X_np = column_transformers.fit_transform(X_df)
pipeline_cox2 = make_sklearn_survival_pipeline(
CoxProportionalHazard(),
max_time=max_time,
)
sfs = SequentialFeatureSelector(pipeline_cox2,
k_features= 1,
forward=False,
scoring=integrated_brier_score_administrative_sklearn_scorer,
cv=5,
n_jobs=5)
sfs.fit(X_np,y)
SequentialFeatureSelector(estimator=SklearnSurvivalPipeline(max_time=818,
steps=[('coxproportionalhazard',
CoxProportionalHazard())]),
forward=False, k_features=(1, 1), n_jobs=5,
scoring=make_scorer(integrated_brier_score_administrative_sklearn_metric, greater_is_better=False, response_method='predict'))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| estimator | SklearnSurviv...nalHazard())]) | |
| k_features | (1, ...) | |
| forward | False | |
| floating | False | |
| verbose | 0 | |
| scoring | make_scorer(i...hod='predict') | |
| cv | 5 | |
| n_jobs | 5 | |
| pre_dispatch | '2*n_jobs' | |
| clone_estimator | True | |
| fixed_features | None | |
| feature_groups | None |
Parameters
| alpha | 0.0 | |
| max_iter | 25 | |
| solver | 'newton' | |
| ties | 'breslow' | |
| tol | 1e-09 |
fig = plot_sfs(sfs.get_metric_dict(), kind='std_err')
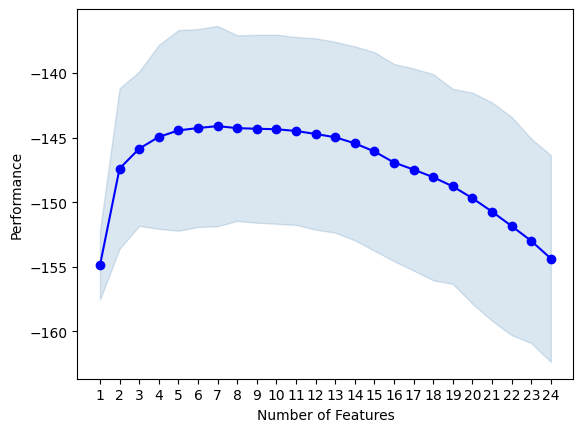
step_wise_feature_selection_results = pd.DataFrame.from_records(sfs.subsets_).T
step_wise_feature_selection_results.sort_values('avg_score',ascending=False).head(5)
| feature_idx | cv_scores | avg_score | feature_names | |
|---|---|---|---|---|
| 7 | (2, 12, 13, 16, 18, 20, 22) | [-143.56667782179701, -136.2559405565069, -159... | -144.112512 | (2, 12, 13, 16, 18, 20, 22) |
| 6 | (2, 12, 13, 16, 18, 22) | [-143.83516942714164, -135.87268885869483, -15... | -144.263809 | (2, 12, 13, 16, 18, 22) |
| 8 | (2, 12, 13, 15, 16, 18, 20, 22) | [-141.46966297859967, -138.3577477928492, -157... | -144.270329 | (2, 12, 13, 15, 16, 18, 20, 22) |
| 9 | (2, 12, 13, 15, 16, 18, 19, 20, 22) | [-149.19738821435038, -135.5058462894316, -155... | -144.318642 | (2, 12, 13, 15, 16, 18, 19, 20, 22) |
| 10 | (2, 8, 12, 13, 15, 16, 18, 19, 20, 22) | [-149.00292841678186, -134.64053897377698, -15... | -144.356467 | (2, 8, 12, 13, 15, 16, 18, 19, 20, 22) |
best_features_idxs = list(step_wise_feature_selection_results.iloc[7]['feature_idx'])
best_features_names = column_transformers.get_feature_names_out()[list(best_features_idxs)]
best_features_names
array(['standardscaler__num_hrt', 'standardscaler__num_surv6m',
'standardscaler__num_num_co', 'standardscaler__num_surv2m',
'standardscaler__num_adls', 'standardscaler__num_sps',
'standardscaler__num_adlp', 'standardscaler__num_scoma'],
dtype=object)
cross_val_score(
pipeline_cox2,
X_np[:,best_features_idxs],
y,
scoring=integrated_brier_score_administrative_sklearn_scorer,
).mean()
np.float64(-144.2703290803045)
best_features_col_names = [i.split('__')[1] for i in column_transformers.get_feature_names_out()[list(best_features_idxs)]]
strat_cols = ['fac_sfdm2', 'fac_sex']
cols = best_features_col_names + strat_cols
X_df2 = X_df[cols]
strata_transformers = make_strata_column_transformer(
(StrataBuilderEncoder(), strat_cols)
)
column_transformers = make_column_transformer(
(StandardScaler(), best_features_col_names ),
)
pipeline_cox3 = make_sklearn_survival_pipeline(
strata_transformers,
column_transformers,
CoxProportionalHazard(),
max_time=max_time,
)
Using both the best strata and best features, we are able to get the best performing model so far.
cross_val_score(
pipeline_cox3,
X_df2,
y,
scoring=integrated_brier_score_administrative_sklearn_scorer,
).mean()
np.float64(-112.16788210122328)