Survivalpredict general walkthrough¶
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
%matplotlib inline
from survivalpredict.estimators import CoxProportionalHazard, ParametricDiscreteTimePH, KaplanMeierSurvivalEstimator, KNeighborsSurvival, CoxNeuralNetPH
from survivalpredict.strata_preprocessing import StrataBuilderDiscretizer, StrataBuilderEncoder
from survivalpredict.metrics import brier_scores_administrative, integrated_brier_score_administrative
from survivalpredict.validation import sur_cross_val_score
from survivalpredict.model_selection import Sur_GridSearchCV
from survivalpredict.datasets import load_iranian_telecom_churn
from sklearn.preprocessing import StandardScaler
#loading some stock data
iranian_telecom_churn = load_iranian_telecom_churn()
#X is our design matrix/features
X_raw = iranian_telecom_churn['X']
ss = StandardScaler()
X = ss.fit_transform(X_raw)
times = iranian_telecom_churn['times'].astype(np.int64)
events = iranian_telecom_churn['events'].astype(np.bool_)
column_names = iranian_telecom_churn["column_names"]
A quick note on time
The times array should be the last known interval of survival, regardless of whether the individual experienced the event (i.e., death, churn, conversion) or is still ‘alive’ or in an unknown state. The times array is assumed to possess the type of integer for ‘survivalpredict’. It is up to the user to encode the time array. It is recommended, if possible, to maximize the times array to a few thousand for significant datasets. Presence of large times can trigger a lot of computation for various estimators. It is common to map time to the age of an entity, like the length of time of an individual as a customer.
times
array([38, 39, 37, ..., 18, 11, 11], shape=(3150,))
times.max()
np.int64(47)
Events
The ‘events’ array should indicate if an individual has experienced the event of interest. Meaning that if said individual has churned, failed, converted or whatever else, at the time interval; the row is coded as ‘True’, and ‘False’ if otherwise. It is assumed to be boolean, or castable to boolean type.
events
array([False, False, False, ..., False, False, True], shape=(3150,))
The estimators of survivalpredict are very much like scikit-learn’s. But on fit,instead of estimator.fit(X,y) we call estimator.fit(X,times,events)
cox = CoxProportionalHazard()
cox.fit(X,times,events)
CoxProportionalHazard()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| alpha | 0.0 | |
| max_iter | 25 | |
| solver | 'newton' | |
| ties | 'breslow' | |
| tol | 1e-09 |
#getting coef for each feature
dict(zip(map(str,column_names), map(float,cox.coef_)))
{'call_failure': 0.49002110564486184,
'complains': 0.4642420003531521,
'charge_amount': -0.4260444138054183,
'seconds_of_use': 0.3941831629069322,
'frequency_of_use': -2.243512319411528,
'frequency_of_sms': -2.8807741511861256,
'distinct_called_numbers': -0.3472067201427454,
'age_group': -0.38608148133212045,
'tariff_plan': 0.25561928662332745,
'status': -0.033874900032043305,
'age': 0.2751268870965148,
'customer_value': 1.7624310169629172}
When we call .predict on an estimator, we will get the predicted survival curve for each individual. Each row in the predicted array corresponds to the row we ran predict on. Each column represents a point in time, starting with the ‘1’ interval of the ‘times’ array we trained on. By default, the right-most column goes till the max time seen in the training data, but we can set the max time by the max_time key word argument on predict.
max_time=times.max()
preds = cox.predict(X,max_time=max_time)
times_of_survival_curve = np.arange(1,max_time +1)
pd.DataFrame(preds, columns=times_of_survival_curve)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 0.999408 | 0.999112 | 0.998663 | 0.998061 | 0.996686 | 0.995914 | 0.994508 | 0.993721 | ... | 0.842658 | 0.808461 | 0.776371 | 0.741665 | 0.701823 | 0.643917 | 0.558087 | 0.508759 | 0.508759 | 0.508759 |
| 1 | 1.0 | 1.0 | 0.997211 | 0.995816 | 0.993709 | 0.990884 | 0.984458 | 0.980866 | 0.974346 | 0.970715 | ... | 0.445828 | 0.366663 | 0.302876 | 0.244086 | 0.188098 | 0.125289 | 0.063789 | 0.041219 | 0.041219 | 0.041219 |
| 2 | 1.0 | 1.0 | 0.999992 | 0.999988 | 0.999981 | 0.999973 | 0.999954 | 0.999943 | 0.999924 | 0.999913 | ... | 0.997631 | 0.997058 | 0.996499 | 0.995868 | 0.995106 | 0.993920 | 0.991951 | 0.990680 | 0.990680 | 0.990680 |
| 3 | 1.0 | 1.0 | 0.998926 | 0.998389 | 0.997575 | 0.996483 | 0.993992 | 0.992596 | 0.990053 | 0.988631 | ... | 0.732897 | 0.679804 | 0.631619 | 0.581303 | 0.525864 | 0.449769 | 0.346909 | 0.293267 | 0.293267 | 0.293267 |
| 4 | 1.0 | 1.0 | 0.999431 | 0.999146 | 0.998715 | 0.998136 | 0.996814 | 0.996072 | 0.994720 | 0.993963 | ... | 0.848265 | 0.815148 | 0.784021 | 0.750301 | 0.711515 | 0.654991 | 0.570839 | 0.522253 | 0.522253 | 0.522253 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3145 | 1.0 | 1.0 | 0.999934 | 0.999901 | 0.999851 | 0.999784 | 0.999630 | 0.999544 | 0.999386 | 0.999298 | ... | 0.981096 | 0.976575 | 0.972176 | 0.967232 | 0.961296 | 0.952112 | 0.937048 | 0.927430 | 0.927430 | 0.927430 |
| 3146 | 1.0 | 1.0 | 0.999998 | 0.999997 | 0.999995 | 0.999993 | 0.999988 | 0.999986 | 0.999981 | 0.999978 | ... | 0.999403 | 0.999258 | 0.999117 | 0.998957 | 0.998765 | 0.998465 | 0.997966 | 0.997644 | 0.997644 | 0.997644 |
| 3147 | 1.0 | 1.0 | 0.999724 | 0.999585 | 0.999376 | 0.999094 | 0.998451 | 0.998090 | 0.997431 | 0.997063 | ... | 0.923162 | 0.905473 | 0.888507 | 0.869731 | 0.847590 | 0.814180 | 0.761564 | 0.729351 | 0.729351 | 0.729351 |
| 3148 | 1.0 | 1.0 | 0.999927 | 0.999890 | 0.999835 | 0.999760 | 0.999589 | 0.999494 | 0.999319 | 0.999221 | ... | 0.979040 | 0.974034 | 0.969165 | 0.963696 | 0.957134 | 0.946990 | 0.930375 | 0.919783 | 0.919783 | 0.919783 |
| 3149 | 1.0 | 1.0 | 0.992660 | 0.989003 | 0.983493 | 0.976136 | 0.959527 | 0.950323 | 0.933752 | 0.924600 | ... | 0.118763 | 0.070918 | 0.042839 | 0.024246 | 0.012195 | 0.004176 | 0.000704 | 0.000223 | 0.000223 | 0.000223 |
3150 rows × 47 columns
We can also visualize some of our predicted survival curves.
n_failed_to_show = 5
n_censored_to_show = 5
n_rand_rows_to_show = n_failed_to_show + n_censored_to_show
random_rows_failed = np.random.choice( np.arange(0,preds.shape[0] )[events.astype(np.bool)] ,size=n_failed_to_show, replace=False)
random_rows_censored = np.random.choice( np.arange(0,preds.shape[0])[~events.astype(np.bool)] ,size=n_censored_to_show, replace=False)
n_rand_rows_to_show = np.concat((random_rows_failed,random_rows_censored))
np.random.shuffle(n_rand_rows_to_show)
fig, axs = plt.subplots(len(n_rand_rows_to_show))
fig.set_figheight(13)
fig.set_figwidth(7)
for a,i in enumerate(n_rand_rows_to_show):
axs[a].set_ylim(0.0,1.05)
axs[a].plot(preds[i],color='b')
if events[i]:
axs[a].axvline(x = times[i], color = 'r', label = 'event')
else:
axs[a].axvline(x = times[i], color = 'g', label = 'event',linestyle='--')
fig.tight_layout()
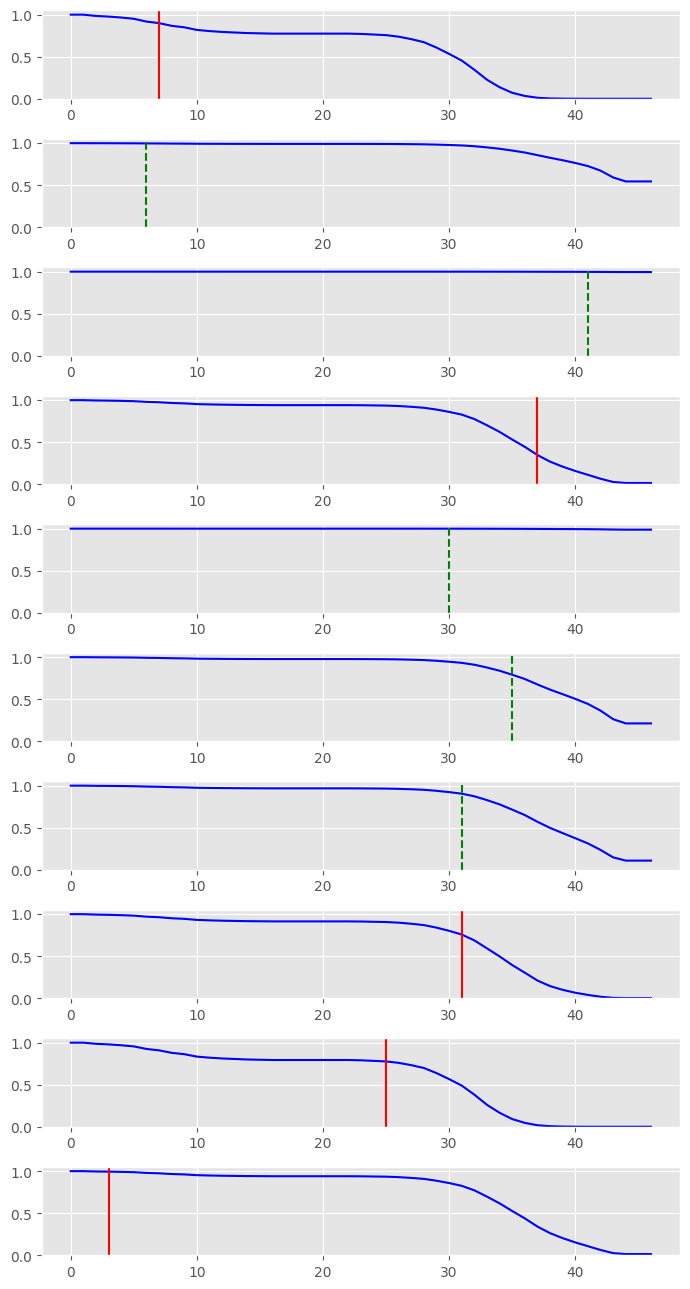
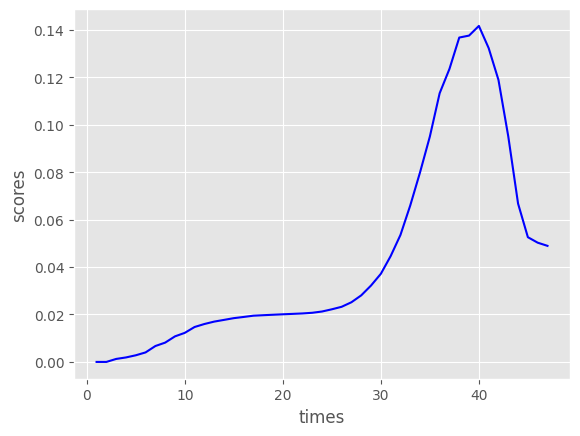
Within survival analysis literature, it is not uncommon to use some form of the ‘brier score’ to assess the performance of a model’s predicted survival curves. Lower the values the better.
scores = brier_scores_administrative(preds,times,events)
plt.xlabel('times')
plt.ylabel('scores')
plt.plot(times_of_survival_curve,scores,color='b')
[<matplotlib.lines.Line2D at 0x7f79ac4cb610>]
The integral of the ‘brier scores’ are used as a singular metric.
integrated_brier_score_administrative(preds,times,events)
np.float64(2.013212241801232)
Within statistical learning methodologies, cross-validation is considered an important cornerstone of prediction evaluation. ‘survivalpredict’ comes with some tooling to evaluate models with cross-validation.
sur_cross_val_score(CoxProportionalHazard(solver='BFGS'),
X,
times,
events,
brier_score_max_time=max_time,
cv=10,
scoring='integrated_brier_score_administrative').mean()
#Quick note on the solver for Cox.
#It is very common for the literature to advise using the Newton method.
#However, the Newton method sometimes leads to errors/issues during training.
#Switching to a quasi-Newton method, like ‘BFGS’, will usually circumvent most issues.
np.float64(2.154072846083714)
It is a good idea to compare the performance of your models against the Kaplan Meier univariate survival curve. This would be analogous to sklearn’s dummy estimators.
sur_cross_val_score(KaplanMeierSurvivalEstimator(),
X,
times,
events,
brier_score_max_time=max_time,
cv=10,
scoring='integrated_brier_score_administrative').mean()
#the lower the better, it seems that the cox model has a lower integrated brier score than the dummy KaplanMeier model.
np.float64(4.815747737919164)
If you wish to train a model with strata, fitting becomes ‘estimator.fit(X,times,events, strata=strata)’. and predict becomes ‘estimator.predict(X, strata=strata)’. The strata array should be an array with integer values. We also have tools for building strata. It is common practice to remove the column/columns used to build the strata.
#getting the position of the age column of the numpy array
position_of_age_col = int(
np.argwhere(column_names == "age")[0][0]
)
age = X[:, position_of_age_col]
sbd = StrataBuilderDiscretizer(n_bins=3,strategy='uniform')
strata = sbd.fit_transform(age)
X_without_strata = X[:,~np.isin(range(X.shape[1]), position_of_age_col)]
cox_with_strata = CoxProportionalHazard()
cox_with_strata.fit(X_without_strata,times,events,strata=strata)
_ = cox_with_strata.predict(X_without_strata,strata=strata)
We can see a significant improvement in the cross-validation score after adding the strata to our cox model.
sur_cross_val_score(CoxProportionalHazard(solver='BFGS'),
X_without_strata,
times,
events,
brier_score_max_time=max_time,
cv=10,
strata = strata,
scoring='integrated_brier_score_administrative'
).mean()
np.float64(2.0188249624572534)
we can also make our strata from categorical data.
StrataBuilderEncoder().fit_transform(['a','b','b','c'])
array([0, 1, 1, 2])
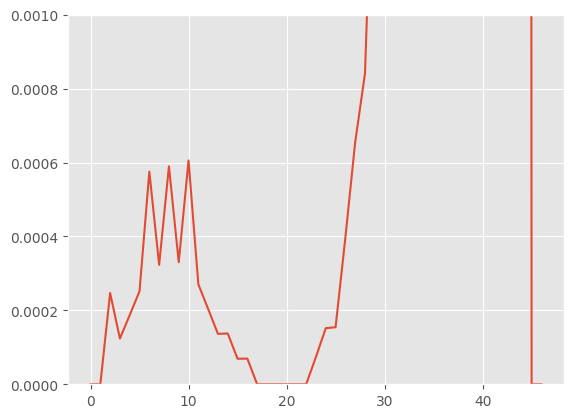
On Base Hazards
The Cox Proportional Hazards model famously avoids estimating the base hazard. Rather, it uses Breslow’s non-parametric estimator for relative risk. The Breslow estimator is simply a function of the sum of failures and the total relative risk at each interval of time. This can lead to stepwise and sporadic base hazard. See here.
#notice the 0's at different points in time
cox._breslow_base_hazard
array([0.00000000e+00, 0.00000000e+00, 2.46954674e-04, 1.23709204e-04,
1.87298265e-04, 2.51698365e-04, 5.75271773e-04, 3.23114334e-04,
5.89668367e-04, 3.30168266e-04, 6.05697370e-04, 2.70504667e-04,
2.03750785e-04, 1.36494564e-04, 1.37367117e-04, 6.90944001e-05,
6.94031201e-05, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 7.42043554e-05,
1.51866879e-04, 1.54275282e-04, 3.97057560e-04, 6.54863996e-04,
8.40568635e-04, 1.62743031e-03, 2.12102358e-03, 2.60234046e-03,
4.43974904e-03, 6.78225246e-03, 8.06410715e-03, 1.06365848e-02,
1.20606415e-02, 1.66947474e-02, 1.72839331e-02, 1.68974268e-02,
1.90796886e-02, 2.30366459e-02, 3.59254315e-02, 5.96820986e-02,
3.86078813e-02, 0.00000000e+00, 0.00000000e+00])
plt.plot(cox._breslow_base_hazard,)
#zooming in
plt.ylim(0.,.001)
(0.0, 0.001)
The ParametricDiscreteTimePH estimator allows us to estimate a proportional hazards model with its coefficients and base-hazard concurrently. ParametricDiscreteTimePH has multiple options for the base hazard distributions. The typical hazard distributions are implemented: namely, “weibull”,”log_normal”,”log_logistic”,”gamma” and “gompertz”. The flexible “chen” and “additive chen weibull” are present as well. It should be noted that ParametricDiscreteTimePH is far more expensive to train than Cox, and cannot be blindly used in most situations. Be careful to set ‘pytensor_mode’ to ‘NUMBA’ or’FAST_COMPILE’ when using multiprocessing, as JAX is not multiprocessing safe. ParametricDiscreteTimePH is using pymc under the hood, and we have access to both the coefficient and base hazards priors via the ‘coef_prior_normal_sigma’ and ‘base_harard_prior_exponential_lam’ parameters, respectively.
pph = ParametricDiscreteTimePH(distribution='chen',pytensor_mode='JAX')
pph
ParametricDiscreteTimePH()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| distribution | 'chen' | |
| alpha | 0.0 | |
| l1_ratio | 0.5 | |
| pytensor_mode | 'JAX' | |
| strata_uses_pytensor_scan | False | |
| coef_prior_normal_sigma | 1.5 | |
| base_harard_prior_exponential_lam | 5.0 | |
| scipy_minimize_method | 'L-BFGS-B' |
pph.fit(X,times,events)
integrated_brier_score_administrative(pph.predict(X,max_time=max_time),times,events)
An NVIDIA GPU may be present on this machine, but a CUDA-enabled jaxlib is not installed. Falling back to cpu.
np.float64(2.368922849108123)
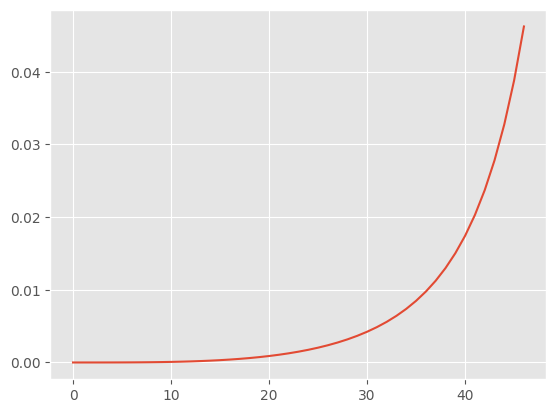
We can easily interpret that ParametricDiscreteTimePH’s base hazard.
plt.plot(pph.get_base_hazard())
[<matplotlib.lines.Line2D at 0x7f79a7fe3d90>]
pph.coef_
array([ 0.36387475, 0.45423797, -0.11316963, 0.42097301, -2.23271764,
-1.92065642, -0.41782933, 0.21545313, 0.24167876, -0.43505684,
-0.55561674, 0.67399218])
We can also run the ParametricDiscreteTimePH with strata. Each strata will have its own distribution. In cases where different distribution structures exist per strata, it is recommended to run one of the Chen family distributions, as they roughly approximate other univariate hazard distributions.
pph_with_strata = ParametricDiscreteTimePH(distribution='chen', pytensor_mode='JAX',coef_prior_normal_sigma=5,alpha=10)
pph_with_strata.fit(X_without_strata,times,events,strata=strata)
pph_with_strata_predict = pph_with_strata.predict(X_without_strata,strata=strata)
integrated_brier_score_administrative(pph_with_strata_predict,times,events)
np.float64(2.8279628658605)
pph_with_strata.coef_
array([ 0.40687347, 0.42951339, -0.3305831 , 0.93308611, -2.72010907,
-2.02502348, -0.05842524, -0.29847454, 0.26244753, -0.40758455,
0.50917766])
pph_with_strata.base_hazard_prams_
array([[6.93149940e-05, 5.60039363e-04],
[3.57473537e-03, 4.33337473e+00],
[3.44572251e-04, 1.84062042e-01]])
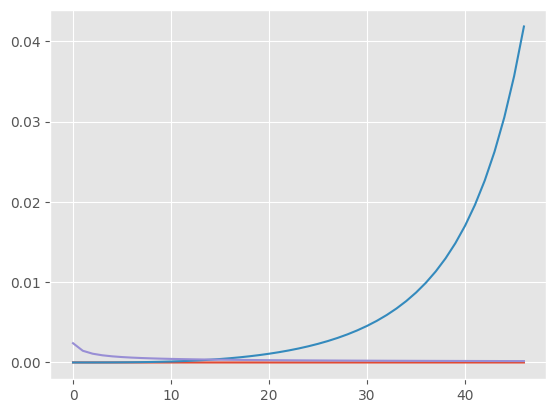
#base hazard per strata
#plt.ylim(0.,.0001)
plt.plot(pph_with_strata.get_base_hazard().T)
[<matplotlib.lines.Line2D at 0x7f7948233610>,
<matplotlib.lines.Line2D at 0x7f7948233750>,
<matplotlib.lines.Line2D at 0x7f7948233890>]
#this will take a while, feel free to skip this
sur_cross_val_score(ParametricDiscreteTimePH(distribution='chen',pytensor_mode='JAX',coef_prior_normal_sigma=5,alpha=10),
X_without_strata,
times,
events,
brier_score_max_time=max_time,
cv=10,
strata = strata,
scoring='integrated_brier_score_administrative'
).mean()
np.float64(2.405528238098512)
pph_with_strata = ParametricDiscreteTimePH(distribution='additive_chen_weibull', pytensor_mode='JAX')
pph_with_strata.fit(X_without_strata,times,events,strata=strata)
pph_with_strata_predict = pph_with_strata.predict(X_without_strata,strata=strata)
Non-interpretive models and GridSearchCV
We also have access to models that lack interpretive power, like K-Nearest Neighbors and Neural networks.
sur_cross_val_score(KNeighborsSurvival(),
X,
times,
events,
brier_score_max_time=max_time,
cv=10,
).mean()
np.float64(1.6548719818337863)
nn = CoxNeuralNetPH(hidden_layers=[50],max_iter=150)
nn.fit(X,times,events)
#quick note, we can also stratify the CoxNeuralNetPH model
CoxNeuralNetPH(hidden_layers=[50], max_iter=150)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| hidden_layers | [50] | |
| alpha | 0.0 | |
| l1_ratio | 0.5 | |
| init_dis | 'uniform' | |
| track_loss | True | |
| max_iter | 150 | |
| gradient_updater | 'adam' | |
| learning_rate | 0.01 | |
| beta1 | 0.9 | |
| beta2 | 0.999 | |
| epsilon | 1e-07 | |
| rho | 0.95 | |
| decay | 0.9 |
integrated_brier_score_administrative(nn.predict(X,max_time=max_time),times,events)
np.float64(1.1817339060413794)
sur_cross_val_score(CoxNeuralNetPH(hidden_layers=[50],max_iter=150),
X,
times,
events,
brier_score_max_time=max_time,
cv=10,
).mean()
np.float64(1.4255965419773156)
Finally, it should be noted that we have access to hyperparameter tuning tools, much like scikit-learn.
grid = {'n_neighbors':[5,10,50,100]}
knn_gscv = Sur_GridSearchCV(estimator=KNeighborsSurvival(),cv=10,param_grid=grid)
#warning, this will take a while
knn_gscv.fit(X,times,events)
Sur_GridSearchCV(cv=10, estimator=KNeighborsSurvival(),
param_grid={'n_neighbors': [5, 10, 50, 100]})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| estimator | KNeighborsSurvival() | |
| param_grid | {'n_neighbors': [5, 10, ...]} | |
| brier_score_max_time | None | |
| scoring | None | |
| n_jobs | None | |
| refit | True | |
| cv | 10 | |
| pre_dispatch | '2*n_jobs' | |
| error_score | nan | |
| return_train_score | False |
KNeighborsSurvival()
Parameters
| n_neighbors | 10 | |
| algorithm | 'auto' | |
| leaf_size | 30 | |
| p | 2 | |
| metric | 'minkowski' | |
| metric_param | None | |
| n_jobs | None |
gscv_results = pd.DataFrame(knn_gscv.cv_results_)
gscv_results.sort_values('rank_test_score').head(5)
| params | param_n_neighbors | rank_test_score | mean_fit_time | std_fit_time | mean_test_scores | std_test_scores | split0_test_score | split1_test_score | split2_test_score | split3_test_score | split4_test_score | split5_test_score | split6_test_score | split7_test_score | split8_test_score | split9_test_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | {'n_neighbors': 5} | 5 | 1 | 0.010494 | 0.007529 | 1.586677 | 0.383159 | 2.392802 | 1.629911 | 1.200597 | 1.703998 | 1.904668 | 1.306964 | 1.741952 | 1.307275 | 1.692615 | 0.985988 |
| 1 | {'n_neighbors': 10} | 10 | 2 | 0.007740 | 0.000246 | 1.654872 | 0.379803 | 2.265041 | 2.003174 | 1.114686 | 1.754821 | 1.994142 | 1.795310 | 1.407095 | 1.546741 | 1.675230 | 0.992480 |
| 2 | {'n_neighbors': 50} | 50 | 3 | 0.007534 | 0.000114 | 2.069845 | 0.484736 | 2.308040 | 2.066184 | 1.935281 | 2.568745 | 2.515525 | 2.754340 | 2.284523 | 1.576388 | 1.438373 | 1.251052 |
| 3 | {'n_neighbors': 100} | 100 | 4 | 0.008318 | 0.000998 | 2.299540 | 0.527179 | 2.295040 | 1.984076 | 2.146886 | 2.724492 | 2.934456 | 3.182299 | 2.660396 | 1.832815 | 1.703744 | 1.531201 |
knn = KNeighborsSurvival(**gscv_results[gscv_results['rank_test_score'] == 1]['params'].values[0])
sur_cross_val_score(knn,
X,
times,
events,
brier_score_max_time=max_time,
cv=10,
).mean()
np.float64(1.5866770434755766)